浅谈正则表达式
30分钟正则从入门到精通,我之前也对正则望而生畏,平时工作中或多或少会遇到正则,但也就仅限或多或少了,希望能和大家一起温故而知新
工具
可视化
正则大全
起步
基础扫盲
特殊字符
^ // 匹配行的开头
$ // 匹配行的结尾
. // 任意字符
\d // 数字
\w //[0-9a-Z_]
\b // 单词边界 \w与^ $ \W之间的位置, 之前这部分也没理解清楚hello.hi world
//\bhello\b \bworld\b
'hello world'.replace(/\b/g, 'b') //'bhellob bworldb'
//\bhello\b.\bhi\b \bworld\b
'hello.hi world'.replace(/\b/g, 'b') // 'bhellob.bhib bworldb'
\s // 空格
\D \W \B \S // 取反
2
3
4
5
6
7
8
9
10
11
12
13
范围
[abc] 表示 'a'、'b'、'c' 中的任意一个,也就是 或 [a-z]、[1-5] 表示范围, [0-9a-Z] 表示 0-9 或者 a-Z, [\w-] 表示 字母 或 连字符 - [^abcd] 表示匹配 a、b、c、d 以外的 字符,这种写法用以 排除
量词
* 匹配 0~∞ 个 + 匹配 1~∞ 个 ? 匹配 0 or 1 个,相当于 {0,1} {n} 匹配 n 个 {n,m} n - m个 {n,} 匹配 >= n 个
lastIndex

const reg = /\d/g
const str = '01qwer'
console.log(reg.lastIndex) // 0
reg.lastIndex = 3
reg.test(str) // fasle
reg.lastIndex // 0
reg.test(str) // true
reg.lastIndex // 1
reg.test(str) //true
reg.lastIndex // 2
reg.test(str) // false
reg.lastIndex // 0
2
3
4
5
6
7
8
9
10
11
12
修饰符
g 全局搜索
'hello wolrd hello regex'.replace(/hello/g, 'hi') //hi wolrd hi regex
'hello wolrd hello regex'.replace(/hello/, 'hi') //hi wolrd hello regex
2
3
i 忽略大小写
'Hello wolrd'.replace(/hello/, 'hi') // Hello wolrd
'Hello wolrd'.replace(/hello/i, 'hi') // hi world
2
3
m 多行匹配 之前我理解是只匹配第一行,第二行开始不匹配了 ^ 每行会匹配一次开头 $ 同理
'play football'.replace(/football/, 'basketball') // play basketball
'play \nfootball'.replace(/football/, 'basketball') // play \nbasketball
'play football'.replace(/^football/, 'basketball') // play football
'play \nfootball'.replace(/^football/m, 'basketball') // play \nbasketball
2
3
4
5
u 使用unicode码的模式进行匹配
https://github.com/xitu/gold-miner/blob/master/TODO/upcoming-regexp-features.md

s 允许 . 匹配换行符
/hello .* regex/m.test(`hello world
regex`)
// false
/hello .* regex/s.test(`hello world
regex`)
// true
2
3
4
5
6
7
y 执行“粘性(sticky)”搜索,匹配从目标字符串的当前位置开始,具体可以参照 https://javascript.info/regexp-sticky
The flag y makes regexp.exec to search exactly at position lastIndex, not “starting from” it.
let str = 'let varName = "value"';
let regexp = /\w+/y;
regexp.lastIndex = 3;
console.log(regexp.test(str)) //false
regexp.lastIndex = 3;
console.log(regexp.exec(str)); // null (there's a space at position 3, not a word)
regexp.lastIndex = 4;
console.log(regexp.test(str)) //true
regexp.lastIndex = 4;
console.log(regexp.exec(str)); // varName (word at position 4)
2
3
4
5
6
7
8
9
10
11
12
13
匹配位置
正则表达式是匹配模式,要么匹配字符,要么匹配位置 匹配字符很好理解,那什么是匹配位置,很多文章会这样介绍
^xx表示以 xx 开头xx$表示以 xx 结尾 并且很多时候我们也会写出这样的正则比如/^\d+$/,可是如果这样生硬的记住的话,有一些正则就变得不好理解了
'hello world'.replace(/^/, 'zhao大建') // zhao大建hello world
'hello world'.replace(/(?=\w)/g, '*') // *h*e*l*l*o *w*o*r*l*d
2
3
4
位置的概念 ^ $ \b \B (?=) (?!) (?<=) (?<!)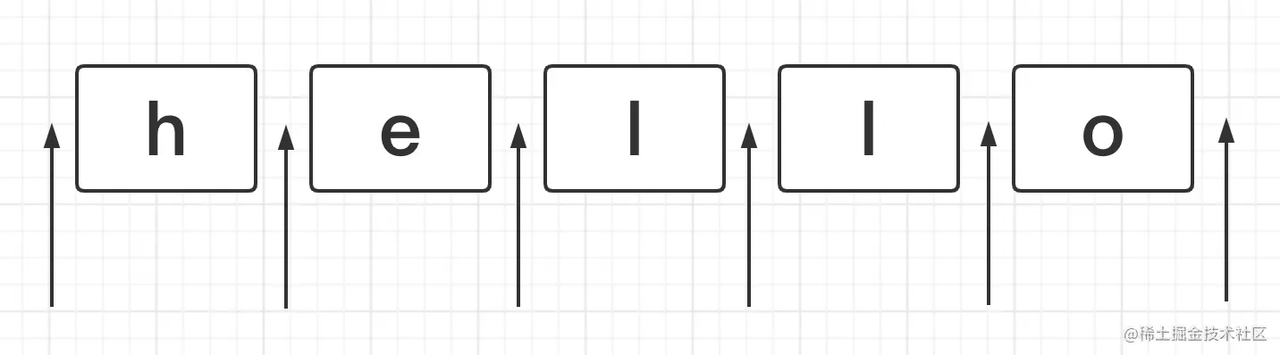
但如果断言后面有跟具体的匹配字符,匹配的是字符,而不是位置了

贪婪模式和惰性模式
正则表达式在匹配的时候默认会尽可能多的匹配,叫贪婪模式。通过在限定符后加 ?可以进行非贪婪匹配 比如 \d{3,6}默认会匹配6个数字而不是3个,在量词 {}后加一个 ?就可以修改成非贪婪模式,匹配3次
let str = `123 456`
str.match( /\d+ \d+?/) // 123 4
str.match(/\d+ \d+/) // 123 456
2
3
断言
先行时字符串放前面,pattern 放后面;后行时字符串放后端,pattern 放前面。先行匹配以什么结尾,后行匹配以什么开头,能匹配的是正向,不能匹配的是负向。
先行正向断言
Positive Lookahead (?=pattern) 表示之后的字符串能匹配 pattern
const regex = /Item(?=10)/;
console.log(regex.test("Item6")); // false
console.log(regex.test("Item10")); // true
2
3
4
5
先行负向断言
Negative Lookahead (?!pattern)表示之后的字符串不能匹配 pattern
const regex = /Item(?!10)/;
console.log(regex.test("Item6")); // true
console.log(regex.test("Item10")); // false
2
3
4
5
后行正向断言
Positive Lookbehind (?<=pattern)表示之前的字符串能匹配 pattern
const regex = /(?<=10)Item/;
console.log(regex.test("10Item")); // true
console.log(regex.test("6Item")); // false
2
3
4
5
后行负向断言
Negative Lookbehind (?!<!pattern)表示之前的字符串不能匹配 pattern
const regex = /(?<!10)Item/;
console.log(regex.test("10Item")); // false
console.log(regex.test("6Item")); // true
2
3
4
5
捕获组
使用 (),作用是提取相匹配的字符串,使量词作用于分组或实现或的效果
编号捕获组
后向引用时使用\1 \2,反向引用使用$1 $2
命名捕获组
命名捕获组可以给正则捕获的内容命名,多变场景下,建议使用,不会随着编号变化有调整,不用每次有啥调整还要数括号,语法是(?<name>pattern),后向引用时使用\k<nmae>,反向引用使用lt;name>
const re = /(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/;
非捕获组
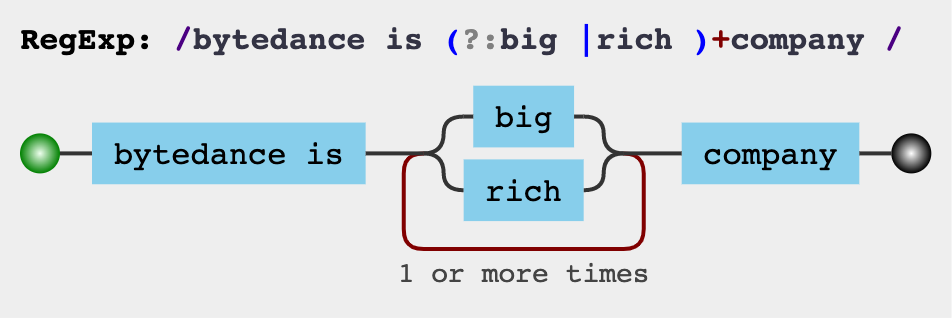
非捕获组?:不需要被引用的, 仅仅是为了能让括号内的部分作为整体,相比捕获组会有性能提升
/bytedance is (?:big|rich) company/ //或整体
/bytedance is (?:big)+ company/ //量词整体
/bytedance is (?:big|rich)+ company/ //整体
// 想要实现一致的话就需要捕获
/bytedance is (big|rich)\1* company/.test('bytedance is bigrich company') //false
2
3
4
5
6
引用
捕获了当然是为了引用的
后向引用
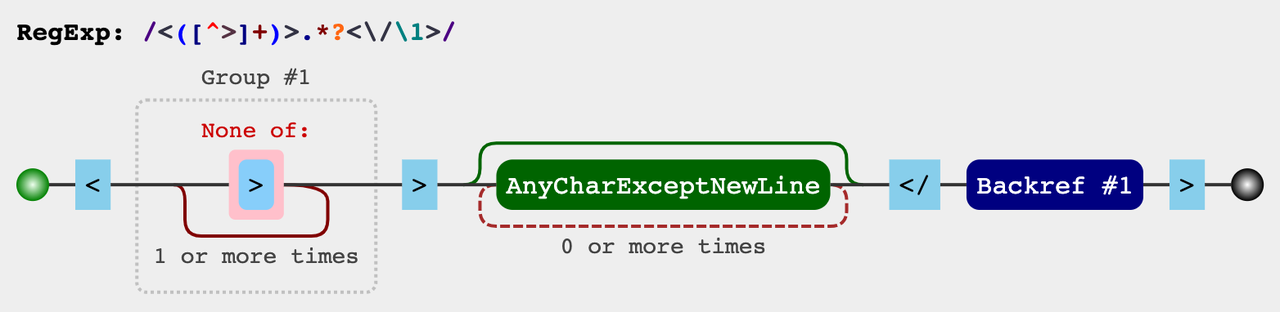
\n 表示后向引用, \1是指在正则表达式中,从左往右数第1个 ()中的内容;以此类推, \2表示第2个 () 判断是否成对标签
/<([^>]+)>.*?</\1>/
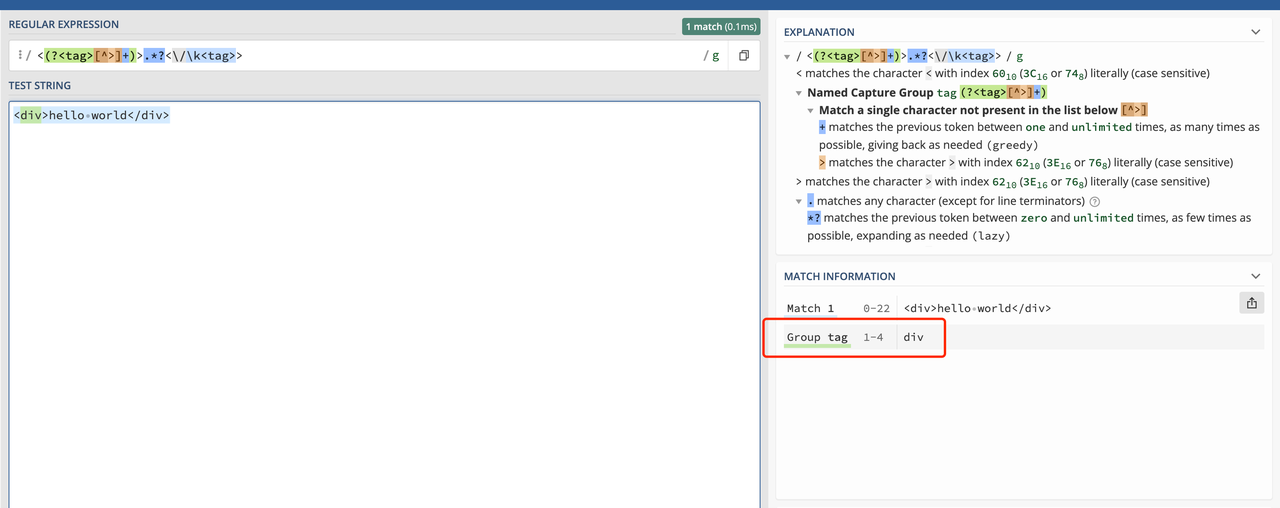
/<(?<tag>[^>]+)>.*?<\/\k<tag>>/
反向引用
使用 ()后可以使用 $1- $9等来匹配
'2022-02-01'.replace(/(\d{4})-(\d{2})-(\d{2})/, `$2-$3,$1`) // 02-01,2022
'2022-02-01'.replace(/(?<year>\d{4})-(?<month>\d{2})-(?<day>\d{2})/, `lt;month>-lt;day>,lt;year>`) // 02-01,2022
2
混用
当编号和命名混用时,编号是怎么算的
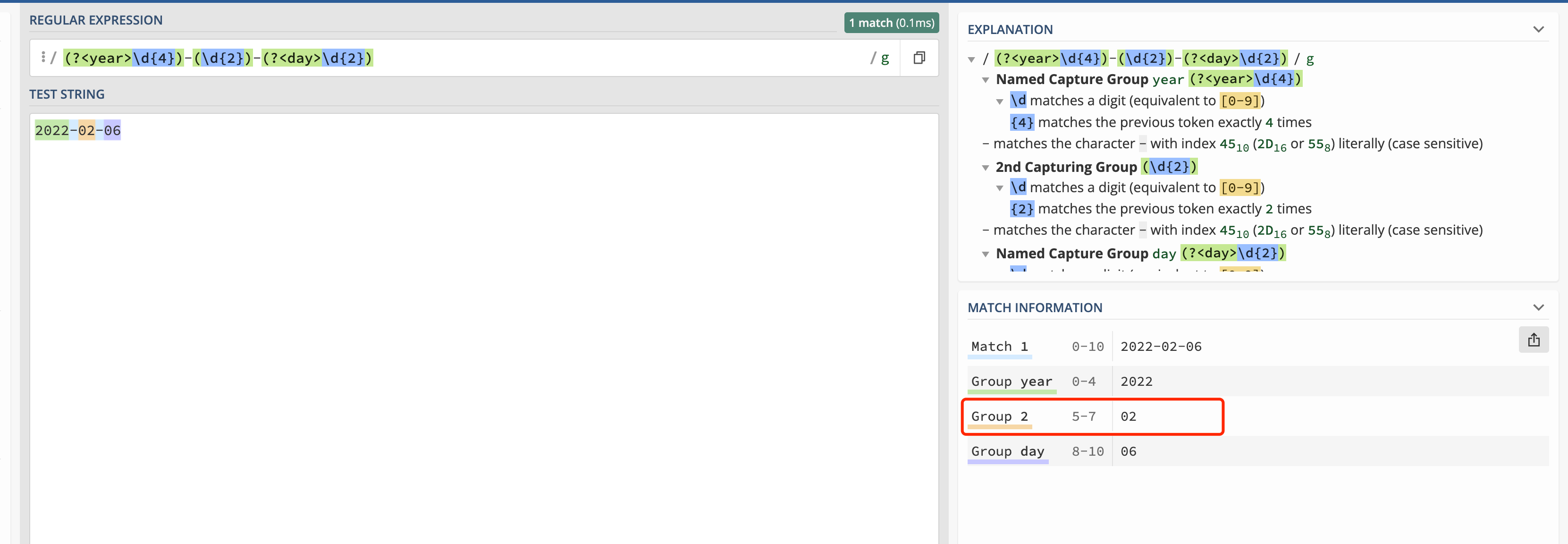
/(?<year>\d{4})-(\d{2})-(?<day>\d{2})/g
一些实战题
不可以是某个字符串
如果我想这个字符串不包含yellow,天真的写下了/[^yellow]/
/(?!yellow)./ 表示非 yellow 的任意元素
/((?!yellow).)*/ 表示非 yellow 的任意元素可以 >=0 次出现。
/^(((?!yellow).)*)$/ 表示从头至尾,必须非 yellow 的元素才能 >= 0 次出现。
/^((?!yellow).)*$/ 后面不能有yellow
/^(.(?<!yellow))*$/ 前面不能有yellow
// 匹配 bytedance is xxx company // xxx不能是small或者poor
/bytedance is (?!small).+ company/.test('bytedance is small company') // false
/bytedance is (?!small).+ company/.test('bytedance is big company') // true
/bytedance is (?!(small|poor)).+ company/.test('bytedance is poor company')
// smallxxx不允许出现
/bytedance is (?!small).+ company/.test('bytedance is smallsmall company') // false
// 允许smallxxx出现
/bytedance is (?!\bsmall\b).+ company/.test('bytedance is smallsmall company') // true
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
数字的千分位分割法
123456789 => 123,456,789
/(?=(?:\d{3})+$)/g取出所有逗号的位置,再去掉首位的逗号\B
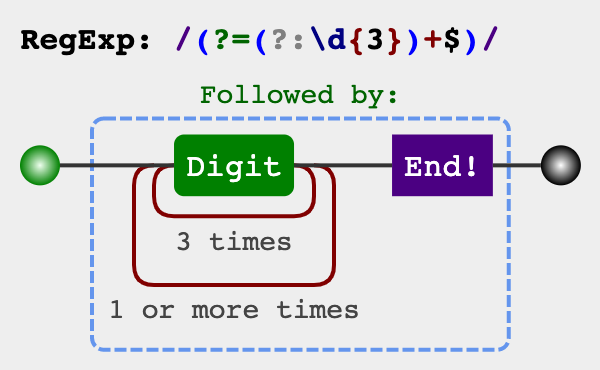
'123456789'.replace(/\B(?=(?:\d{3})+$)/g, ',') // 123,456,789
驼峰化
// -moz-transform => MozTransform
const camelize = (str) => {
return str.replace(/[-_\s]+(\w)/g, (_, $1) => $1.toUpperCase())
}
console.log(camelize('-moz-transform')) // MozTransform
// 更通用的一个方案
const camelize1 = (str) => {
return str.replace(/(?:\b|-)(\w)/g, (_, $1) => $1.toUpperCase())
}
console.log(camelize('router-view'))
2
3
4
5
6
7
8
9
10
11
MatchAll
Regex的一个新特性
var regexp = /t(e)(st(\d?))/g;
var str = 'test1test2';
str.match(regexp);
// Array ['test1', 'test2']
// 获取分组的详细信息
let array = [...str.matchAll(regexp)];
array[0];
// ['test1', 'e', 'st1', '1', index: 0, input: 'test1test2', length: 4]
array[1];
// ['test2', 'e', 'st2', '2', index: 5, input: 'test1test2', length: 4]
// exec方式
let match;
while ((match = regexp.exec(str)) !== null) {
console.log(`Found ${match[0]} start=${match.index} end=${regexp.lastIndex}.`);
// Found test1 start=0 end=5.
// Found test2 start=5 end=10.
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20